DAPO
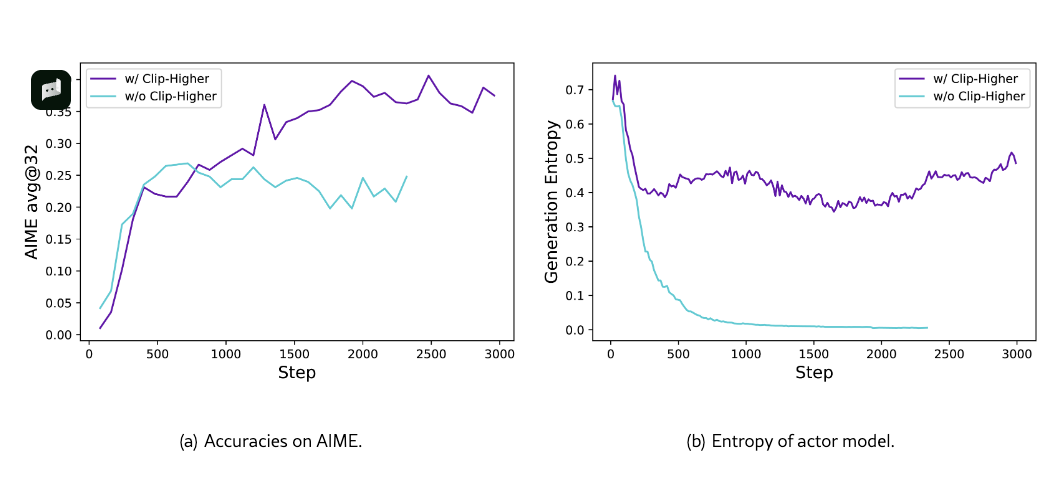
Clip-Higher
传统clip为什么会导致墒崩塌:对于那些概率已经很高的 Token(利用 Token),算法非常宽容,允许它们迅速占据统治地位(接近 1.0)。这会导致模型很快就只愿意说那几句”稳妥的话”,而失去了寻找更好答案的动力。
Key to Token-level loss
传统GRPO中,每个样本在最终损失计算中被赋予了相同的权重,导致长回答中对整体损失的贡献可能会表现得比较低。
Dynamic sampling
去掉奖励为全0或者全1的组
去掉KL散度
因为数据集是数学问题,所以推理路径比较固定,可以去掉,其他数据集未必可以去掉
Overlong Filtering
在生成最大长度的基础上,增加了一个Soft Overlong Punishment,不直接强行截断回答,这样会添加噪声。当回答长度超过设定的最大回答长度并落入惩罚区间内时,随着响应长度增加,对于长度的奖励也会增加。
example: “因此,这道题的答案是”---->reward=0 “因此,这道题的答案是32”---->reward=1
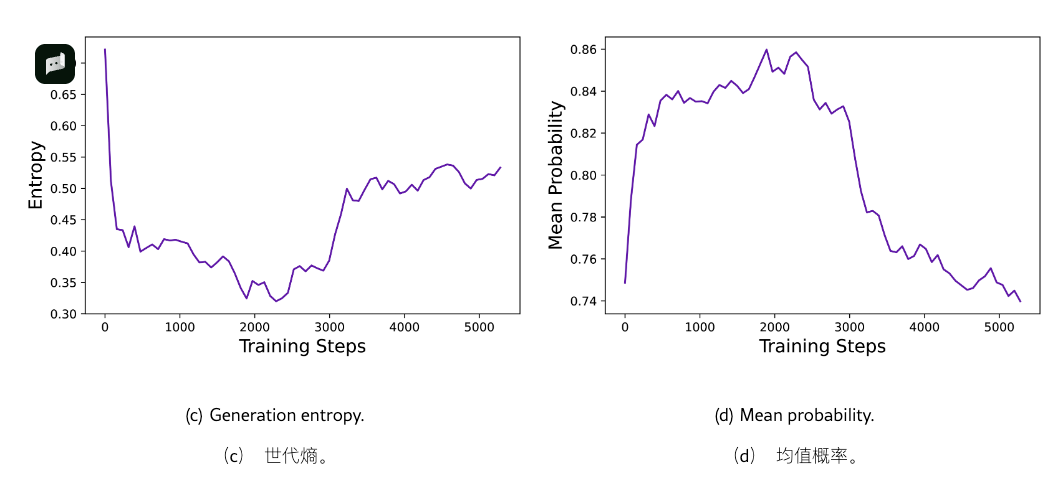
缓慢的熵增有助于提升模型性能
Case study
反思行为的出现: However, wait a moment, let’s rethink about the dihedral angle involving planes in a more thoughtful geometric way. Consider the plane α1=ABC, which lies entirely on the xy coordinate plane (as z=0). Let the plane α2=SBC. The point A projected perpendicularly to plane α2 lands on H. The line l=AB …